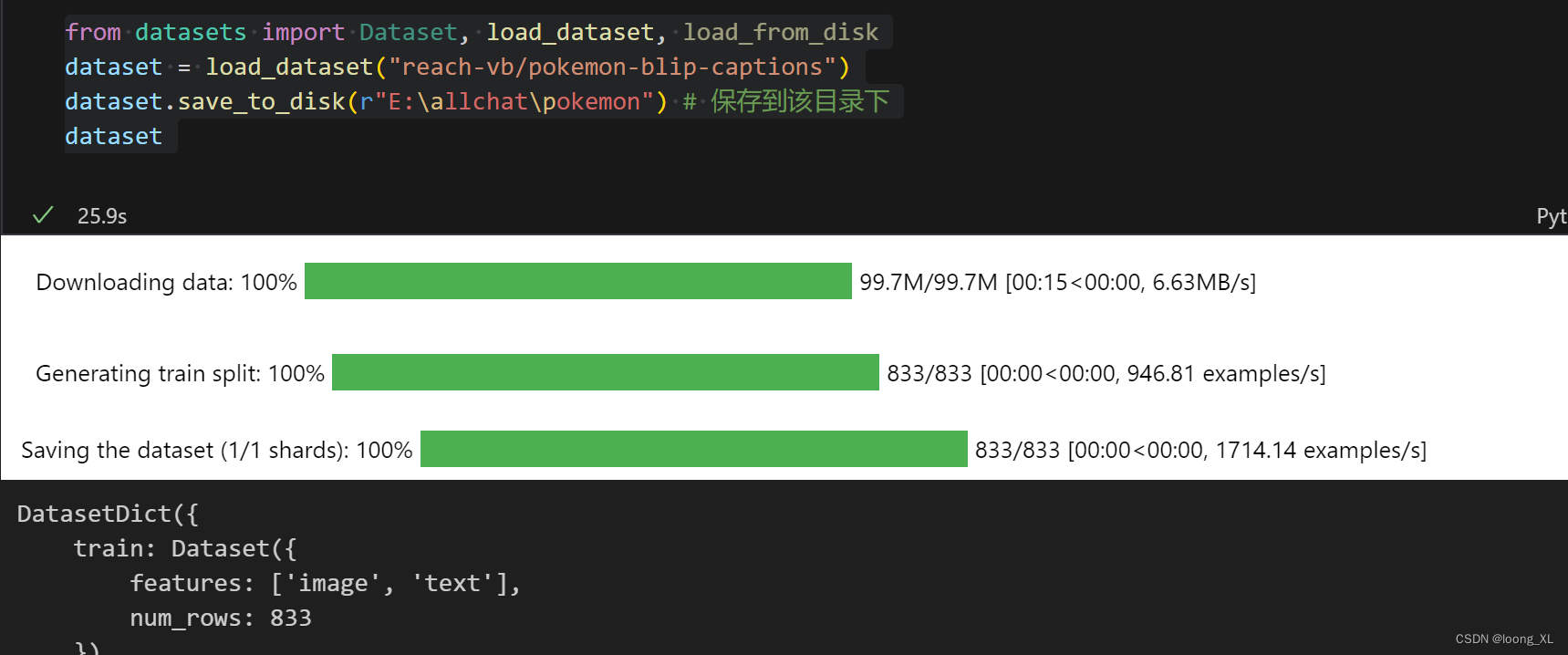
XVDPU是可以提高CNN计算的速度和延迟,他的目标不是直接替换软件在传统硬件或者通用GPU上实现CNN运算。他的目标就是加速CNN计算。
XVDP的实现方式:CNN卷积计算的是 原始图形矩阵{x行*y列*通道数a}*卷积滑块{w行g列t通道}=卷积后的图形{m行*n列*通道数b}
所以xvdpu的实现:
第一个就是硬件矩阵乘法 MAC计算:乘法+累加
因为这里会有矩阵行列的限制,所以遇到大矩阵,就需要把矩阵拆分为多个矩阵进行计算,但这时候卷积滑块是固定的,需要保留卷积滑块在一个共享的存储中,以供多批次多AIE核心的共享使用,同样在读取原始图形时,已要一次加载到一个快速存储中供买个AIE核进行读取部分需要的块进行计算,但下一次读取其他块内容已是能从这个快速访问的存储中读取数据。
所以就引出来xvdpu的存储实现:
vxdpu中存储分为ddr外部存储,pl中的共享特征图缓存,Pl中的共享权重缓存,aie整列中每个aie核的内部存储。数据流动是 ddr->pl特征图+Pl共享权重->AIE内核存储。只有在第一层是要从ddr加载特征图和权重数据道pl缓存,只有在最后一层输出omf的时候要从pl缓存写到ddr4。所以这里就还需要用来移动数据的控制器,在vxdpu中有两个datamove和load引擎,datemove是在PL上:把数据从ddr->PL缓存(特征图和共享权重),PL缓存->aie阵列本地存储。 Load引擎是在aie核内:aie本地存储->AIE的MAC计算器
所以就引出aie mac在计算的时候数据单位:
aie核的mac计算能力,这里设计的是2*8*8. 128*int8 操作。
aie核读取特征图是每个aie核都有单独的axi接口,读取能力是128字节,aie核读取共享权重是有个共享axi接口,读取能力是512字节.
所以就引出xvdpu的整体模块有哪些:
| ddr | 外部存储 | |
| ps | 运行vitis ai工具 | |
| pl | pl中的共享特征图缓存 | |
| pl中的共享权重缓存 | ||
| pl中的DATAMOVE数据移动器 | ||
| pl中ALU计算器 | ||
| aie | aie阵列 | |
| aie核心mac计算引擎 | ||
| load引擎 | ||
| aie本地存储 |